|
Neuma Technology Inc. provides the world's most advanced
solution to manage the automation of the software development lifecycle.
|
|||


More white papers:Find out more ... |
Neuma White Paper:Workspace Management Front and Center
Workspace Management has been an increasingly important component of CM over the years. Gone are the days when the only workspace operations were checkout, checkin, build/make, and the occasional file merge operation. Today, the workspace is at the center of a developer's interaction with the CM tool. Ideally, the workspace is not just a file holder, but embodies an entire development context. More and more that context is accessed through a richer CM tool interface, or from an IDE environment, or even through the file system. So that in the modern CM tool, the workspace must actively provide guidance to the developer rather than lying dormant waiting for a developer to manage it. In the 1970's, we had a "tempdir" and a "permdir," with 2 to 20 MB of disk space allocated to each developer. Checked out source code would go into the permanent directory, while intermediate data, which would disappear with each logoff, went into the temporary directory. No tree structure, no 200 character file names, no graphical user interface. It was pretty simple, but effective. Because of disk space limitations, we learned to create workspaces which were incremental to shared workspaces, which in turn were incremental to system-wide workspaces. In my world, as CM developed over the years, these simple but key capabilities remained important. But there was much more that needed to be addressed. Typically in a CM environment, you can indicate the view of the world you want to deal with: product, development stream/release, promotion level, specific changes, a baseline, a build, etc. You tell the system the context-based view you want to look at. But there's another view as well - the workspace view. You can indicate a workspace and then ask to compare your view to the workspace. So if my context view is set to a specific build or release, I can ask the system: What's different between my workspace and this release? And if your workspace is older you can even ask to synchronize it with your context view. In some simpler CM tools, the only context view you can specify is the "latest" view, or perhaps the view on a certain date. And this works fine for projects which can live with this model. In more advanced tools, you can specify your view in a number of different ways: this stream of this product, the build from last weekend, the same one used by this change, the last shipped release. Ideally, these are done simply from the user interface, and not by having to invent a complex specification. Basic Workspace Parameters The workspace view is typically rather simple, but not necessarily so. Workspace organizations can be categorized along a number of lines. These include the following:
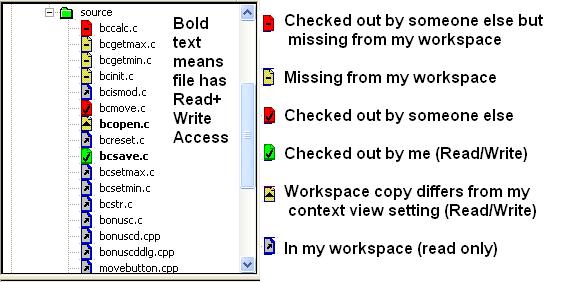
Shared Workspace vs. Parallel Workspaces Some developers create a separate workspace for each change. Others create a single workspace for all of the changes leading up to a release. Many IDEs support the latter methodology only. The CM tool needs to support both modes of operation. The workspace should be an attribute of a change package, or if you depend on branching to simulate changes, an attribute of the private branch. When code is checked out for a change, it goes to the workspace associated with that change, regardless of your current/default working directory setting. Similarly, the change's workspace is used for check-in operations, change delta/difference reports and merge operations. This allows a great deal of flexibility without always having to switch the user's current working around.Read-Write Only on Checkout I like to have write access to all the files in my workspace. This way I can experiment with some changes before I decide that the approach, or even the idea, is a good one. Others like to force a read-only attribute on files which have not been checked out. In this way, they don't accidentally forget to check out a file into a change. The CM tool itself should not have to rely on this attribute to track checked out files. At the same time, it can take advantage of the attributes to take some short cuts. For example, when comparing a workspace to a context view, perhaps the read-write files are compared first, or are the only ones presented. Flat Pool Workspaces vs. Tree Structured WorkspaceIn the old days (1970s), the world was divided in two: Unix and non-Unix. Non-Unix-like systems typically used a flat directory to hold the source code for a product. Unix-like systems typically used a tree-structure to organize its source code. This latter organization was needed initially as an optimization technique for large programs so that the compiler would not have to search large directories for source files (especially header files). But the tree structure also did a good job in organizing the design, and so it persisted even as computers became hundreds and thousands of times faster. A flat pool workspace is simple and convenient - all of the files are in a single directory. It's easy to search and there's only one file by any given name. Today, across all platforms, flat pool workspaces are quite common for smaller programs, or for specific sub-products/subsystems within a larger system. Because of their convenience they should continue to be supported by today's CM tools. One way to help support them is to allow logical design tree-structuring within the tool, while permitting deployment to either tree or pool based workspace structures. Tree structured workspaces can be further divided into those where the workspace tree structure must represent the entire product tree (or a subset, but with a full path up to the product root), and those where the workspace maps onto a specific sub-tree of the entire product tree. Ideally, I would like to point to a design sub-tree in the CM tool and have the option of deploying it in a workspace representing a pool organization, a product tree organization, or a sub-tree organization. Other operations such as check-in, check-out, delta, merge, etc., should also support the selected option. For example, although I might compile the program in a pool-based workspace, it's quite likely that the deliverables (help files, executables, configuration and data files, etc.) will need to be deployed to a specific sub-tree organization. Incremental vs. Full Workspaces Most programs are reasonably small in size (hundreds to a few thousand source files). To compile and link them takes a few seconds to a few minutes. Retrieving them from the CM repository should take significantly less time, though some CM tools are notorious in this area. It is common for developers of such programs to work with full workspaces, retrieving all the source in their workspace needed to build the application. Other programs are quite large, a few thousand to tens of thousands of files. Although some CM tools can retrieve these files quickly, it is often preferable to use incremental workspaces in large projects. In an incremental workspace, only the source files that are modified are retrieved to the workspace. The remainder are accessed from a shared disk pool for the specific context (e.g. latest integration tested source code or latest submitted source code). Full workspaces require a re-synchronization operation, ideally at the control of the workspace owner, when the test environment provided by the workspace starts to become dated. Incremental workspaces do not need re-synchronization (except where parallel check outs are supported). However, they do require some assistance from either or both of the CM tool and the building tools (compilers, linkers, etc.). The virtual file system of ClearCase permits a straightforward means of using incremental workspaces. Search Order In some cases, this assistance can be provided by the Operating System. The VMS Operating System, for example, allows a directory to be defined which is actually a search order of other directories. So a directory can really be a search path which says - first look in my workspace, then the group's shared directory, then the integration-tested directory for the source files. Although I haven't seen the feature used much, SUN Microsystems introduced a disk or directory layering capability a few years back. I'm a bit surprised that the entire Unix community did not take up this feature, as far as I know anyway. Nor has Microsoft, at least not to my knowledge. Neuma Technology's CM+ tool introduced search paths early in the 1990's and relies on it to enrich it's functionality, especially in the area of builds. ClearCase has an even more flexible search order capability using a virtual file system capability whereby the operating system can see a view of files given by a configuration specification. In general, the search order capability allows a workspace to behave as both an incremental and full workspace at the same time. Having a search order within the CM tool has its advantages. For example, in CM+, within the guidelines it suggests, Make files can be generated as part of the build procedure such that intermediate archive libraries do not have to be built. Instead, CM+ uses the same Object Library search order the linker uses to search for object files (or to predict their existence based on the compiles that are to be done) and then creates generic (i.e. GNU compatible) Make files with the correct directory/object file path hard coded - which is fine since the Makefile is thrown away until the next build operation. In this way, search order allows the CM tool to expand the workspace concept beyond source file management and into the realm of the IDE, be it a simple Make tool or integration with an existing commercial or open source IDE. Workspace as a View A workspace is, in a lot of ways, just a different view of your repository, especially with the more advanced Virtual File System and Search Order capabilities. But it's also a lot different. It's a sandbox and is changing. There may be many such sandbox workspaces. It contains not only repository worthy files, but all sorts of intermediate files, from editor backups to compiled object code to files that just happen to be lying around. As such, there are many different ways to look at it. There's the file system view, which shows basically everything. There's the IDE view which shows that portion of your workspace that's important to your IDE. Then there's the CM view which shows your repository-based files, but hopefully a lot more. Active Workspace Management I use the phrase Active Workspace Management to refer to a feature of a CM tool where it tells you about your workspace without you having to ask. Some very simple tools have these capabilities, some very complex ones don't. They're important. What do I want my CM tool to tell me? Well for starters, if I'm looking at a source tree, I want to be able to tell at a glance if a file is checked out or not. Even better, distinguish between my checkouts and those of some other user. I may want to distinguish read-write files from read-only files. And I want to know which files in my workspace are different from the context view I've set.
What else can active workspace management do for you? If someone checks out another file, I want an indicator to appear. If someone checks in a file in my view, I want to see an indicator showing that my workspace file is now different, even if I haven't changed it. It would also be nice to know if a file is missing from my workspace or perhaps disappears suddenly from my workspace, because it was moved through some other user interface. The idea is that I can identify attributes and conditions as a normal part of looking through my source tree. I don't have to pull each bit of status information out by querying the CM repository or by looking at a directory listing. Workspace-Centric Changes I like to go to my to-do list, look at a problem and select fix-it, or look at a feature and select implement-it. A change package is created, I check out files against that change, edit/compile/test, review the change, and check in the change. I'll frequently have several such changes on the go at once, typically all in the same workspace, but packaged into separate changes which trace to the problems and features being addressed. A change package simplifies my workspace work. I still have to check out each file (sometimes multiple files in one step), but I don't have to check in each separately. I don't have to do delta/difference reports on each file. I don't have to promote each file. I can do these operations on the change, whether its for a single file or a dozen files or more. Change packages reduce the workload of a developer and minimizes mistakes (oops, I forgot to check in one of my files). Task-based check-outs also give some of these benefits. But some developers want nothing to do with the CM system, or as little as possible. A good way to introduce these developers to the benefits of a CM tool is to use a more workspace-centric approach. They start out by populating their workspace from the CM tool, or perhaps even populating the CM tool from their workspace. Then they continue to do edits and testing in their workspace. Perhaps once a week they check in their workspace. A decent CM tool can look at a workspace, identify files and directories which have changed, moved or been added/deleted, and then create a change package to encapsulate these changes. There's not as much traceability granularity as creating changes tied to each feature or problem. But at least they have a regular history of how their code is changing. And if all they have to do is drag and drop their workspace root onto the CM tool source tree, they may even be encouraged to do it more than once a week - maybe even after getting each feature implemented or problem fixed! This workspace-centric approach tracks changes by the way the workspace has changed, rather than by the tasks. Is this preferable? No. But it's better than nothing, and hopefully after a few cycles, developers will start taking advantage of their workspace-centric changes and realize that a more regular level of traceability works even better for them. This all assumes that the CM tool makes everything easy and gives payback to the developers. Workspace-centric changes will be a necessity if CM is to move into the realm of non-technical users: lawyers, accountants, secretarial staff. Perhaps the 4th or 5th generation CM tools will update an accountant's files on a daily basis automatically, without a need to expose him/her to a CM user interface. Workspace Meta Data Some CM tools place additional meta data into the workspace. Perhaps to identify source files from intermediate or non-CM controlled files. Perhaps to identify the revision level at which files were checked out. Some tools will insert this meta data right into the source files. Then there's meta data to help your IDE figure out where your workspace is (and what your CM context view is) for each of your projects. With a virtual file system solution, this meta data has to be accessible to the VFS. The same holds for a Tortoise-like file browser based CM user interface. The need for meta data arises from the fact that the workspace can be accessed both from outside the CM tool and from inside. The difficulties arise when file system operations, such as delete and copy, start happening outside of the CM enviornment. How are these to be reconciled with the CM environment. Meta data can help the workspace and CM tools to identify what's going on. The Ideal Workspace So what is the ideal workspace. My ideal workspace supports a series of changes, possibly in parallel, over a long period of time, typically the few years needed from the start of release development until support of that release dies down. I'll use a separate workspace for each development stream. If my object files are located in a directory underneath the source code, I can support multiple platforms with the same code base. Ideally, various C/C++ and Java-based IDEs can work with the same code base. I want to be able to make my changes in one place and then test them on multiple platforms if necessary. I suspect you have your own definition of an ideal workspace. The ideal workspace is an elusive concept. There are too many different types of CM tools, IDEs, application types and work habits. Java is different from Web Content, which is different from C++, etc. Each IDE offers its own take, as does each CM tool. And that's before the users get to define their processes and work habits. So is there any effort to find some standardization? Short term, not much. This means that CM tools will have to broaden their workspace capabilities to deal with the many variations. But the longer term picture will be brighter. This will be driven by the non-technical CM applications - the broader CM market niches which are yet to emerge. These will address CM of Legal Documents, Spreadsheets, Web Sites, and so forth, but with the twist that the end user will be non-technical. The wider base will result in more vertical standardization. Will this overflow into the technical development world? Not through the user base. But the need for vendors to deal with these markets will force them to standardize basic workspace management terminology and functions. Apart from that, standardization will emerge only if one CM solution begins to dominate the market - and in my opinion that's not likely. Quo Vadis? So where is Workspace Management headed? Active Workspace Management will continue to grow and will likely move into the File System domain. But the real advances will come as the power of the CM tool is able to be tapped more fully directly from the workspace. Will the CM interface be replaced by the file system (i.e. workspace) interface, or even by an IDE or other application interface? Yes and no. For basic CM, including change management, this is likely to occur and has already in many cases - users will want to do basic CM from their application interface. And for many of the non-technical vertical applications, this may be the only interface users ever see. But for more complex queries, traceability, reporting, a CM-specific interface will always be preferable. It's possible that you'll see the CM interface evolve such that it addresses the vertical markets directly, much like a File Manager program was used to address the file system application. And within the context of ALM, it's likely that the CM tool will always be necessary to perform lifecycle wide queries and actions. I don't see any application-specific tools (IDE or otherwise) even coming close at this time - not even Eclipse. For ALM, the CM interface will grow into the Manager/Executive/Quality Specialist interface, still used by many developers, but as an alternative - when the vertical application interface falls short. But that's just one opinion. Joe Farah is the President and CEO of Neuma Technology . Prior to co-founding Neuma in 1990 and directing the development of CM+, Joe was Director of Software Architecture and Technology at Mitel, and in the 1970s a Development Manager at Nortel (Bell-Northern Research) where he developed the Program Library System (PLS) still heavily in use by Nortel's largest projects. A software developer since the late 1960s, Joe holds a B.A.Sc. degree in Engineering Science from the University of Toronto.You can contact Joe by email at farah@neuma.com |