|
Neuma Technology Inc. provides the world's most advanced
solution to manage the automation of the software development lifecycle.
|
|||


More white papers:Find out more ... |
Neuma White Paper:Testing and CM - A High Quality MarriageDo you need to improve an area of your team's performance? Measure it and post the results. Over time you will see the performance improve. If you want to improve the quality of your product, measure it. Over time you will see the quality improve. Testing is the key to measuring quality, and CM is an equal partner. A good CM partner will provide both the communication capabilities and the information base to enable the relationships needed for a quality marriage. A good CM suite will help you to organize your test cases, will relate them to the other development artifacts, and will provide a timely sharing of information among all the stakeholders. Test Case Categories Let's start with test case organization. I like to divide test cases into seven basic areas according to the purpose for creating the tests:
Black box testing deals with testing the product without knowing what's inside the box. Your requirements dictate how it is supposed to behave. Your tests verify that behaviour. The establishment of black box test cases flows directly from your product requirements. So should almost all of your product documentation. If your organization has the luxury of working from a fixed set of product requirements, your development, verification and documentation teams can all work in parallel, and can even help each other out by cross-presentation of intermediate deliverables. In many shops, requirements are changing rapidly and dynamically due to new competitive features or the advance of technology components. Although the three teams can still work in parallel, a more iterative approach may be preferable. Another key feature of black box test cases is that they can often survive from one product family to another, largely intact, minimizing the need for full re-development of the test suite when a new product definition is in the works. White box testing deals with testing the product based on what you know about the internals of the product, that is, how it was designed and implemented. In software, a focus might be on testing internal APIs and Message Sequences. White box testing is a key component of modular design. You design a module, by specifying its interfaces, and then build your test suite to those interfaces. Once verified, you know that errors in the product will not be traced back to that module. When object-oriented design is involved, a white box test suite can be used to verify multiple objects which behave according to the class definition. A standard set of test cases may be used to test devices from multiple vendors, for example. Change testing is primarily a developer level test sequence. When a change is made to a product (or a product-to-be), it is the developer's responsibility to ensure that the function of the change can be tested and verified to operate according to the change description. In some cases, this is similar to black box testing. The difference is that the tests are geared to the changes in functionaliy, whether those are the result of a change in requirements, staging the implementation of a feature, identification of non-compliances that must be resolved, etc. The goal is to understand what the intent of the change is and to verify that such intent is met. In our shop, we will non-traditionally refer to this a "unit" testing, where the unit is a "change" rather than a configuration unit. Bug testing serves two purposes: to enable easy replication of a problem in the "before" scenario; and to verify that the problem has been fixed in the "after" scenario. Strictly speaking, a test case to resolve a problem should be spelled out in the problem report itself. This is how to reproduce the problem... <test case>. If I can't reproduce it, it was a transient symptom of some other issue. There may be an underlying problem, but until we can get some better frequency of reproducing the problem, I don't want to do anything more than track the symptom as having occurred. When a new deliverable is being prepared, every problem that is reported as being fixed must pass its test case or it is re-opened. Sanity testing is done to verify the stability of the resulting build or integration. It's purpose is not to identify if specific problems have been fixed or if specific features work as advertized. Instead, the purpose is to ensure that the basic set of functionality is working to approximately the same degree, or better, as the previous build/integration. Later on in the release cycle, sanity testing may be more stringent than earlier on. The sanity tests also verify changes to the build environment. Perhaps new compilers and design tools have been introduced. Perhaps the underlying hardware platform is also evolving. The key output of sanity testing is to indicate whether or not the new deliverable is sufficiently stable to allow the team to continue development in an effective manner. It will ensure that the integrated set of components and the tools used to prepare it are in reasonable shape. Stress testing is sometimes considered a part of black box testing. This is especially true if the product requirements indicate, for example, that there will be no catastrophic behaviour when the product is operated outside of the requirements envelope. It is also part of black box testing when specific parts or operations need to be stressed to a certain level within the envelope. An engine must be re-usable for N hours without maintenance. The database must be able to handle 10,000 transactions per hour. These are stress tests which, strictly speaking, cover the product requirements. As such, they are a special subset of the black box tests. Additional stress tests will fall outside of the product requirements. For example, how long can that engine run without maintenance. How many transactions per hour can the database support. These tests are generally run to "rate" the deliverable or component. Establishing a rating not only makes it easy to assert that a requirement is or is not met, but it also permits the establishment of additional claims such as an MTBF. A light bulb may have an MTBF of 2000 hours, even though the occasional one may fail after 100 hours. From a "spares" perspective, I would likely only need one light bulb, but I might want two or three light bulbs to guarantee a 1000 hour mission time. Beta testing helps to identify the defects resulting from incomplete requirements or imperfect testing. As hard as you might try, requirements are going to be incomplete. A new use case for an existing capability pops up in a customer's head and guess what? It breaks the system. Your testing is not going to be perfect... when I do x,y,z three times and repeat them in the reverse order it prints out a funny message. All of these test cases will need to be managed. They will need hierarchical groupings, change control, revision control, release management, etc. They will also need to be related to other elements of the CM system. Other Categories of Testing There are a number of other test case categories not mentioned above. They do not generate new test cases, but are a grouping or application of the above sets of test cases:
This latter set of categories are quite valid and need to be performed and tracked. They will directly influence the formation and tracking of test runs and test sessions. They will generally not introduce any new test cases. However, they will introduce identifiable test case groupings which will have to be managed. Some of these will already be covered under the Black Box testing organization. Revision and Change Control of Test Cases So how do all of these test categories influence the design of your CM environment. Well there are several areas to consider. First let's look at where the test cases belong and how they are releated to other parts of your CM environment. Test cases are part of your product. They are much like software, yet have significant differences. You may wish to avoid having to name each test case, a task diligently done for software files. Instead, you may just want your CM tool to generate test case identifiers as you add them to the system. You may still wish to group them into named directories or test groups. Test cases come in two basic flavours: automated and manual. The good thing about automated test cases is that they are very easy to run once the test bed has been established. Manual test cases require significant manual effort. As a result, you'll run them less frequently. It is important to track this attribute against each test case, understanding that it will change as you endeavor to automate more and more of your test cases. Test cases, like software, will change over time. They will need revision control. [An exception may exist for change tests and for problem tests.] If they are part of the product, as most black box and white box test cases are, they will need to track the product. When a new software baseline is created, it's likely that you want a new test case baseline following right on the heels. Your release 1 software will have to be maintained and supported. Well, so will your release 1 test cases. If you ever need to re-release, you'll need to re-test. So test cases will have branches which follow release streams in the same way that software does. You will likely wish to manage changes to test cases in much the same way that you manage changes to your software files. Checkout and checkin operations should work with change packages so that you can make related test case changes in a single package. Whether or not you put your test cases through the scrutiny of a CCB is going to be a project decision that may change from time to time. Your CM tool must let you group test cases together. Whether this is done by hierarchical grouping (as in file/directory structures) or by tagging test cases with one or more group tags isn't as important as ensuring that your groupings can change over time. The group definitions will require revision control. Test Case Relationships So how does testing relate to the other parts of your CM environment? These relationships need to be tracked by your CM tool suite. Testing generates problem reports. Here's how I would break it down.
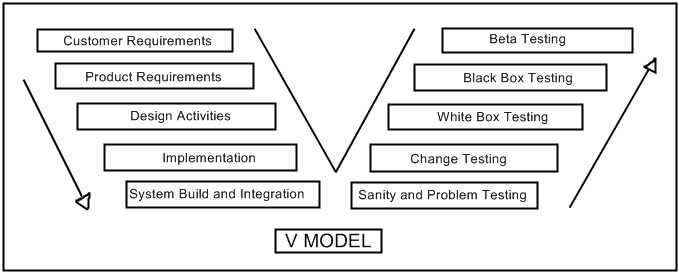
As you can see, problem reports will come in many flavours. The CM tool suite must be able to sort out customer data from development data. It must be able to identify the development phase in which the problems originated. But the CM tool must also be able to relate both the tests and the spawned problem reports to the product development side of the fence. It must be able to address critical questions. Which requirement is the test testing? How far through the integration testing are we? What sort of coverage do our test cases provide? Which test cases are new to this development stream? The V-Model View Another way I like to look at relationships is to use a view which is similar to the one that has come to be known as the V Model.
In the V Model diagram, the Verification activities on the right side of the V address the Development activities on the left side of the V, at the same level. Typically, at least within a build cycle, the activities follow sequentially down the left side of the V and up the right. As such, the horizontal axis is really one of time. The V Model shows a clear relationship between testing and development artifacts. This same relationship should be clearly visible from your CM environment. From Build to Beta To generate a build, the system integration and build team creates a build record identifying exactly what is going into the build. This is used to extract the files required and generate the deliverables. These are loaded onto one or more testing platforms to ensure the basic sanity of the build. Sanity is assessed by running a sanity test suite, a critical first step of which is to "initialize" or "boot" the system. Sanity testing should be tracked against the build record. It should include the baseline of sanity test cases that was used to perform the tests. This is typically a brief regression test suite. It should also contain a list of problem reports generated as a result of the sanity testing. As an extended bit of sanity testing, some of the higher priority "fixed" problems are verified as being fixed. Those not fully fixed should be marked as re-opened. Your CM system should allow you to identify the frequency of re-opening of a problem report. Depending on your shop, developers would use the new build to verify that their changes are working correctly. Some shops do this as part of the implementation process (prior to integration) and some have the integration team do this verification after sanity testing. In any event, developers should verify their changes, and the integration team should independently verify them based solely on the data stored against the change record. Some organizations may even have the developer do a code review with the integration team in order to ensure that the change is exactly what it is supposed to be, and that nothing extra "snuck" in. Change testing, including the test description, the results, and the code review results, should be tracked against the change record. White box testing should be defined as a test case hierarchy running in parallel with or as part of your design hierarchy. This should be no different than your source tree structure. Test cases should exist to exercise all of the internal programming interfaces, as well as any application prograrmming interfaces which are to be exported for use by other applications. Message protocols should also be exercised. White box testing may include running certain black box tests based on the knowledge of the design. Typically, these tests exercise the various success and failure paths of the code. Ideally these tests can be exercised on a module by module basis so that each module may be certified and then itself treated as a black box. When a module is modified, it has to be re-certified. This approach helps to reduce the complexity of white box testing. Black box tests are generally grouped hierarchically into features, often reflecting the structure of the product requirements tree. In some systems it is possible to have the test cases attached directly to each requirement. However, this becomes more complex unless requirements to test cases form a 1:N mapping. Black box testing needs to be done against a specific build. It may be OK to run an entire database of test cases across a series of builds, but in the end, there should be a final run against the candidate build. Successive test case runs over a series of builds will help to establish metrics showing how quality is improving over time. Stream to stream comparisons may give some additional information, such as telling you the effectiveness of a change in development process or tools. A key approach to ensuring that black box testing is effective is to define your requirements for testability. Be clear. If the requirements are not sufficiently detailed, a product specification (such as a detailed user manual), should be developed to help enable better black box test case definition. Don't expect your black box testing to give you a product quality guarantee. Once the product is in the customers' hands, additional problems will arise. A wide beta test effort can help to identify the most common outstanding problems - those most likely to be detected by your customers. Beta testing should not be an excuse for less black box testing. Nevertheless, you need to identify the percentage of problems which find their way through to the beta release. This is a guide that you can use from one release to another. If you change your testing methodology, this percentage may change and you will have some idea as to the effectiveness of the new methodology. At last, you're ready for production. The ultimate test bed. Even a small number of problems will cause you big problems if your production volume is high. But if you've been measuring along the way, you should have a good idea as to the quality of your production product. The best you can add to that is to have a responsive support team. Such a team can turn a product flaw into an opportunity to show your customers that they are important. Test Results Another crucial component of test case integration with your CM environment involves the tracking of test results, or test run data. A Test Run might be defined as a set of Test Cases to be run against a particular build (or perhaps a related series of builds). Typically a test run is completed over some period of time, such as a few days or weeks. The more automation, the faster. As well, a test run is typically completed by multiple testers. I like to break Test Runs down into Test Sessions. Each Test Session identifies a particular tester executing a subset of the Test Run's test cases against a particular build. All of the test session considered together form the test run. Note that variant builds might be tested under the same test run, but only a single build should be used by a given test session. Test sessions can be tracked as actual sessions (i.e. time periods spend by each tester) or they may span time periods for a given tester for a given build. Your test run data, along with your test case repository should allow you to get answers to some basic questions?
I'm sure you can add to this list. The point is that tracking test cases goes beyond the test cases themselves into the running of the test cases. Typically the test case tracking will make it easy to identify passed test cases (as these should be in the majority). As well, an integration with your test environment should make it easy to upload failure results directly into the test run data base. A more tricky capability is to enable a single problem report to be spawned for a multitude of test case failures, all caused by a single problem. For this reason, it is recommended that problem reports from failed test cases either be raised as a result of investigating the cause of the failed test case, or else be raised in a problem report domain different from the development problem domain. Especially with novice testers and those improperly instructed, it is more likely that problem reports raised from test results are going to have a lot of duplication. A failed test case should be treated as a symptom, not a problem. The problem could be a bad test bed, a bad test case, a problem in the software. The first and last of these could easily cause multiple test case failures for a single problem. Special education emphasis and care is needed to avoid having to deal with the administration, and possible rework, from multiple test case failures rooted in the same problem. Beware of test case management systems which track test results (test run information) directly against the test case. Ask these questions:
At a minimum, your CM environment must be able to demonstrate, with confidence, that your verification was completed to your advertised level. Generation of test metrics, summaries, and reports will be important to any company wondering about the stability and reliability of your product. The Final Step When you're ready to go a step further, broaden your defintion of CM to include Customer Management (CRM). Carefully let key design team members visit customer sites where appropriate. This will take the product out of the abstract domain and make it real. Your team members will take quality and testing more to heart. Joe Farah is the President and CEO of Neuma Technology. Prior to co-founding Neuma in 1990 and directing the development of CM+, Joe was Director of Software Architecture and Technology at Mitel, and in the 1970s a Development Manager at Nortel (Bell-Northern Research) where he developed the Program Library System (PLS) still heavily in use by Nortel's largest projects. A software developer since the late 1960s, Joe holds a B.A.Sc. degree in Engineering Science from the University of Toronto. You can contact Joe at |