|
Neuma Technology Inc. provides the world's most advanced
solution to manage the automation of the software development lifecycle.
|
|||


More white papers:Find out more ... |
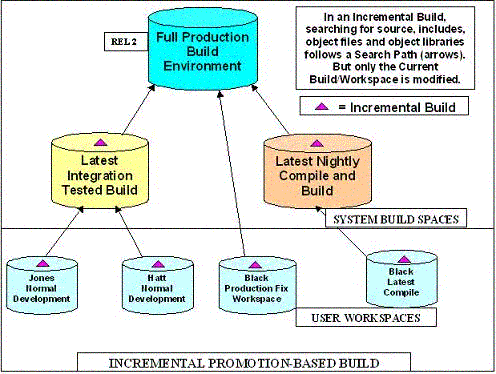
Neuma White Paper:Moving Dependency Tracking Into the CM ProcessLast month I spent a bit of time describing how a CM tool could support the creation and comparison of builds, to support the building of multiple variants, etc. based on a single baseline. This month, I will focus on how the CM tool can simplify the build process, moving the process out of "Make" files while supporting the creation of reusable, layered software. Make (as in Makefile) has been a workhorse in the build scene for as long as I can remember. OK, not quite. Before Make, we were forced to either "compile the world" every time, or build a CM system which could tell us what to compile. When I first used Make, I was surprised at how easy it was to compile only what I needed. At the same time, I was amazed at how complex it could be. Since then, there have been some improvements on the build scene, ANT, Jam and OpenMake among the many. But some of the lessons from the earlier years need to be kept. Who has not been burnt by the "date" mechanism of Make, for example, after restoring an older file when the change to it didn't suffice. Or by the complexity it permits. Impact Analysis The CM environment is the centre of the build universe. It understands (hopefully!) what files there are in the "universe". Many CM systems understand the various file classes: C, C++, Java, Frame, Shell Scripts, etc. It is one thing to deploy a build environment and use a make-like (or more modern) facility to tell you what needs compiling. But a CM tool should be able to tell you the impact of a change before you make it. It should permit you to explore multiple views and assess the impact of a change. It should allow you to take a set of changes (e.g. those check-in for the nightly compile) and tell you which files will need to be compiled, and which changes should be omitted if you wish to avoid a large compile (i.e. because a common header file was changed). In the late 1970's our mainframe CM system was able to tell us what needed to be compiled. Even though there were many thousands of files in millions of lines of code, it took but a few seconds. The reason was that the CM system itself tracked the dependencies between files. We could ask: if I change "timer.h" and "files.h" what has to be recompiled. This was an important tool, not only to determine what the impact of a change might be, but to allow the designer to explore which other ways of implementing the change would have less impact. Software Layering A key feature of this capability was to support the building of re-usable layers of software. By ensuring that no file in one layer depended on any files in the layers above, the code was kept well layered - the lower layers from one project could be used to start development on a parallel product, perhaps not even related to the first. The CM tool could provide this layering enforcement. Without the enforcement of layering, it was difficult to produce reusable code as "include" (or "uses" or "depends on", etc.) relationships crossed layering boundaries freely, creating dependency loops. In fact, its a common practice these days to put conditional compilation instructions in place to break dependency loops (e.g. #ifndef abc-header / #define abc-header /... / #endif). This seems like a fine solution, and it is, as long as you don't want to reuse only a portion (e.g. a layer) of the software. Some languages, such as Modula-2, Ada and Nortel's Protel, even had compiled headers which had to be compiled in a specific order to avoid compile failure. This was actually a good thing, as long as you had an environment which would tell you the correct compile order every time you had to do a compilation. These languages really did help to provide reusable code modules because the dependencies could only go in one direction, from higher layers to lower layers. Impact with Dynamic Views I'm not suggesting that we go back to a world of compiled headers (although some IDEs support this feature for performance reasons). But I am suggesting that the CM system needs to track arbitrary dependencies among its configuration items (CIs). It is the most logical place to track these dependencies because a user can have an arbitrary view of the CIs. Without actually deploying them, it is not easy to identify dependencies for the view. Some CM systems (e.g. Clearcase) allow you to avoid deploying the CIs because it makes the OS view of the file system reflect the actual CM user's view. However, in a system of tens of thousands of CIs, having to traverse the file system to determine dependencies is a time consuming, resource intensive task. If you've ever tried to identify who broke the layering rules, you'll know that a database, even if its only an intermediate one, is necessary to allow you to traverse the dependency relationships repeatedly to help determine the culprit. Putting the Process Where it Belongs Perhaps a more important point - a CM system which tracks dependencies can readily tell you what needs to be re-compiled, without having to rely on date stamps. Instead, only a straight-forward process is required: keep track of the process used to generate your object environment. Then changes to your source (and meta-source) environment can be used by the CM system to determine what needs to be compiled. How about a concrete example. Let's say I'm supporting a development team's object environment and I've just compiled the entire object code for the first time. From this point forward, I can can do incremental compiles. Suppose headers "one.h" and "two.h" were the only header files modified by the changes submitted for the next nightly compile. Then I need only compile all of the changed files plus any files affected by "one.h" and "two.h". The CM system can tell me exactly which files need to be compiled. I don't have to rely on date stamps. The CM system tells me which files to replace in the compile environment, and also which files to re-compile. In fact, it can generate a simple "compile script" which has no dependency information in it. My compile script is now basically a list of items to be recompiled, possibly with the set of compile options for each item. There's great benefit here in that the build process moves out of the Make file(s) and into the realm of the build process suppport of the CM tool. (Ever try to infer the build process from a [set of] Make files?) The process can be defined and applied to any number of make files. The dependency information does not need to be dumped to an intermediate file for interpretation. Full Compiles versus Incremental Compiles Most small and even medium sized projects don't even have to worry about this problem. They just recompile the world every night. What's a few hundred even a few thousand files. And I agree with that strategy - simple is best. If your designers can use the same strategy on their own desktops without a significant delay - compile the world. Its when you get to large projects, or find your developer compiles taking more than a few minutes or find yourselves having to generate dozens of environments nightly that a reliable, incremental compile capability is needed. This is where the CM system should be giving you support. Such a CM tool needs to support the concepts of "affected by" and "affects". It is also useful if it supports the concepts of "used by" and "uses". In addition, if the CM tool can track the "Make" or "compile" rule for each file class and the special purpose Compile options for any CI which has special compile options, it is able to generate compile scripts. Generally, if a CM tool can dynamically generate a Make file, it already has the information it requires to support these concepts and capabilities. If it has a good query capability, the return could be all the greater.
A good CM tool can even generate Make and Build files and scripts which eliminate the need to create intermediate library archives, which are often created so that the link tools can help you to implement promotion levels with incremental compiles. Instead of requiring a full object code directory for each promotion level (checked-in, built, integrated, tested, production, and perhaps team group levels as well), only object code files which change from level to level should need re-compiling and storing at each level, using the next higher level as part of the search order in the linking process. Again, with smaller projects this isn't an issue. But give me a large development project with many variants or customizations across several different target platforms, and the savings add up: compile time, storage, backups, network distribution throughout the design environment, etc. Summing Up It may not change the world, but moving dependency tracking into the CM system
Joe Farah is the President and CEO of Neuma Technology. Prior to co-founding Neuma in 1990, Joe was Director of Software Architecture and Technology at Mitel, and in the 1970s a Development Manager at Nortel (Bell-Northern Research) where he developed the Program Library System (PLS) still heavily in use by Nortel's largest projects. A software developer since the late 1960s, Joe holds a B.A.Sc. degree in Engineering Science from the University of Toronto. |