|
Neuma Technology Inc. provides the world's most advanced
solution to manage the automation of the software development lifecycle.
|
|||


More white papers:Find out more ... |
Neuma White Paper:Making Incremental Integration Work For YouRecent CM Crossroads posts have suggested that a branch-per-change branching strategy is good because it gives you the ability to maintain a stable "main" trunk, while integrating a change at a time if you want. As Joseph Reedick put it in one of his responses:
So the obvious question is: How do I allow a change-by-change integration strategy to proceed without the negative side effects? Perhaps you're normally going to do a small batch of changes and infrequently your batch may be very small. Here's where both good tools and good process are critical. They must support change management. More than that though, they must support incremental development environments, incremental impact analysis and the ability to roll back changes easily. If you're doing more frequent integration cycles, you'll likely want to be able to move on to your next cycle before the current one is completed. As a result you may need multiple promotion levels whereas your previous process may have supported only one or two. There is a key property, which, for some reason, most CM processes and vendors seem not to have caught on to yet. In a broad system of hundreds or thousands of files, most changes will move successfully through the process in the order they're put into the system. This is especially true if you have controls on your product development and support streams which allow you to easily support restricitions on check out operations - or at least on check-in operations. So why is this such a key factor and how have we missed the boat. Most processes and tools are set up to provide stable environments, some promotion levels, etc. To do so, they use branching to support promotion models. This is very flexible because you can have as many branches as you need to support your promotion levels. There's a cost though - in branch and merge operations, along with labeling. Some prefer the "pull" method, where the CM team is responsible for the merging and labeling. Some prefer the "push" method, which developers accept as a cost of having good CM. I prefer neither. The problem with this branching pattern is that it focuses on success for the worst case scenario - and yes it can certainly handle it. But the cost is high. Instead a strategy that focuses on the most typical scenario and still allows the worst case scenario to be handled not only is less costly, but will almost surely result in better unit testing (i.e. developer testing). Basic Assumptions We start out with three basic assumptions about our CM tool and process:
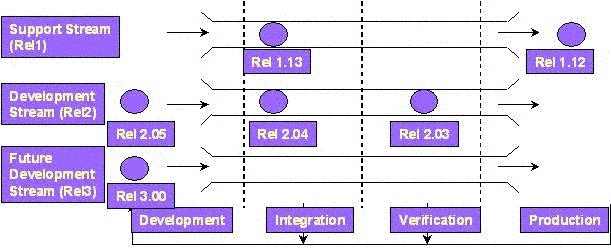
The first assumption says files will follow a branching pattern that reflects that of the product the product. For the product, this does not mean that release 1.00 and 1.02 and 1.03 all have their own project branches. It does mean that release 1, release 2, release 3, and perhaps release 2b, all have their own project branches. A branch-per-release stream strategy will allow us to put things into parallel streams in parallel. No waiting until one stream is finished before starting work on the next (see Diagram). What's more important from a process perspective is that there's no change to the way I work in one stream when the next stream starts out. I set my view or context to the product and stream, and hopefully the CM tool guides me the rest of the way without any complex branching and labeling strategy.
The second assumption says we have a tool that will allow us to branch a file only if it has not yet been branched into the release stream I'm working on and a change needs to be made to it which does not apply to earlier streams. I don't want to branch a file just because I'm starting a new project stream. If I do, then during the first part of the new stream, most of my bug fixes would have to be made in two branches of the file unless I close down changes to the previous stream - and that's a bad reason to force customers to live with what they've got. So, for example, if file A has only a release 1 branch and a new release 3 feature affects this file, only then is a new (release 3) branch created. The CM tool must support this in two ways.
The third assumption says that we have a CM tool suite that allows us to package files into a change, and target the change to a particular release stream. The more advanced the change management, the easier the incremental integration is going to be. For example, as we shall see, we will want change management to support a process model which includes promotion and roll-back operations at the change level (as opposed to the file or problem/feature level). So, we still have requirements for rapid incremental integration. And that means multiple promotion levels as well. We still need to make sure that the development environment is stable. Can we do these things and still avoid a heavy load of branching, merging and labelling? I've been doing CM like that way for over 25 years now, in projects of up to 30+ million lines of code, even though for the first 10 or so years I had to develop tools to support the effort. Guidelines to Simplify Integration Remember the key - changes will normally flow through the system in the order they're developed. Organize your process and tools to make this the simplest case and then deal with the exceptions. So, rather than starting changes off in their own branch, changes will be applied directly to the stream branch. But we'll use a few guidelines and capabilities to help out. These are not hard and fast rules, but rather guidelines that are to be followed to avoid more drastic circumstances.
Incremental Integration So with all of this in place, we'll proceed to do incremental integration as follows:
There are a lot of places where the CM tool is going to be able to help out a lot. From automatic generation of Make/Build files, to promotion violation notices, to support for incremental builds. Some tools (e.g. CM+) will even eliminate the need to build intermediate library archives/dlls in order to do object code sharing. In the end, we've assumed that changes are flowing through the system, pretty much in the order that they've been made - with a bit of allowance for developer push to the "ready" state to co-advance a set of changes. This has eliminated most of the branching and merging work, especially as the developers realize that, with no reason to hold up a check-in operation, the frequency of parallel check-outs drops dramatically. Still we have to allow for disruptive changes. There already is a much better chance that unit testing is going to be done against a more up-to-date and sequentially growing build environment, since there are few, if any, merge operations that need to be completed. But what happens when a change "breaks the build"? Usually, because we are doing frequent integrations, we can simply roll back the change with no impact on other changes. In some cases, we may need to roll back dependent changes as well. But roll-back operations are simple roll-back of the state of the change(s) (i.e. their promotion levels), and a subsequent rebuilding operation. If we can't afford to roll back some changes, we can fix them through a subsequent change, promote that change and do a rebuild. If we want to allow subsequent changes to the rolled back functionality to continue because the roll back will be for an extended time, we "change" the branch tip to reflect the latest acceptable functionality by creating a "new" change which checks-in older acceptable revision(s) and promoting it. Then new changes may continue against this tip. The rolled back functionality will have to be reconciled forward at a later time. The big difference here is that we are dealing with an exceptional case. We are incurring additional overhead in this case (really comparable to the branch, merge, label strategy overhead), but we expect to infrequently have to deal with this kind of exception. More importantly, the file history is much easier to comprehend. The complex branching strategies that have been worked out, reviewed and approved ahead of time, and then mapped onto a number of default context view specifications disappear. The CM tool can easily tell you when you need to branch (assuming it is tracking the product road map, past, present and planned). And because the complexity is reduced, incremental integration is that much easier. Although many of you old-timers who have religiously used branches for promotion level management may be skeptical, it's time to take a closer look. How much time do you spend doing branching, merging, labeling, creating branch and label strategies, creating view configurations? More to the point, how many incremental integration opportunities are either overlooked or scaled back because of the expected overhead? Does your CM Tool Support Incremental Integration Before finishing off, I want to point out additional capabilities that are lacking in most tools, which would be useful in supporting incremental integration.
Reporting and Incremental Integration Finally, it all comes down to knowing what you're doing and what you've done. Even more important than release note generation, I would claim, is the ability to be able to report to the system integration, development and test teams, what has changed in each iteration of incremental integration. In the later stages of a release, this reporting is equally important to the Change Control Board and to the Build Managers. When an incremental build is ready for sanity testing, the first focus is on how well the build initializes. Then, the focus moves to changes in the functionality. You want your teams to have a list of problems resolved and features advanced so that they can first test these out and perhaps establish (or selecdt) an incremental set of test cases to be run. You don't have time to run a full regression test, typically, at least not before you make a go/no-go decision for moving the development environment onto the new build. But it sure is nice if you can quickly focus on fixes and feature areas addressed by the incremental build, because these are the most likely areas where problems will occur. Make sure your tools and processes allow for automated and effective reporting. You can't spend a few hours at it because in a few hours you may well be processing your next integration cycle. Where To From Here Although I've not actually made a case for incremental integration here, it's a way of life at Neuma. If you're going to embark on it, make your life easy:
Then you'll make Incremental Integration work for you, rather than vice versa. Instead, you can tackle the bigger problems, like automatically calling the developer who introduced compile errors, improving your sanity [testing] and getting time off for the holidays. Joe Farah is the President and CEO of Neuma Technology. Prior to co-founding Neuma in 1990, Joe was Director of Software Architecture and Technology at Mitel, and in the 1970s a Development Manager at Nortel (Bell-Northern Research) where he developed the Program Library System (PLS) still heavily in use by Nortel's largest projects. A software developer since the late 1960s, Joe holds a B.A.Sc. degree in Engineering Science from the University of Toronto.
|